This blog post is a supplement to the paper, “‘Style’ Transfer for Musical Audio Using Multiple Time-Frequency Representations”.
Experiment 4.1: Musical Texture Generation
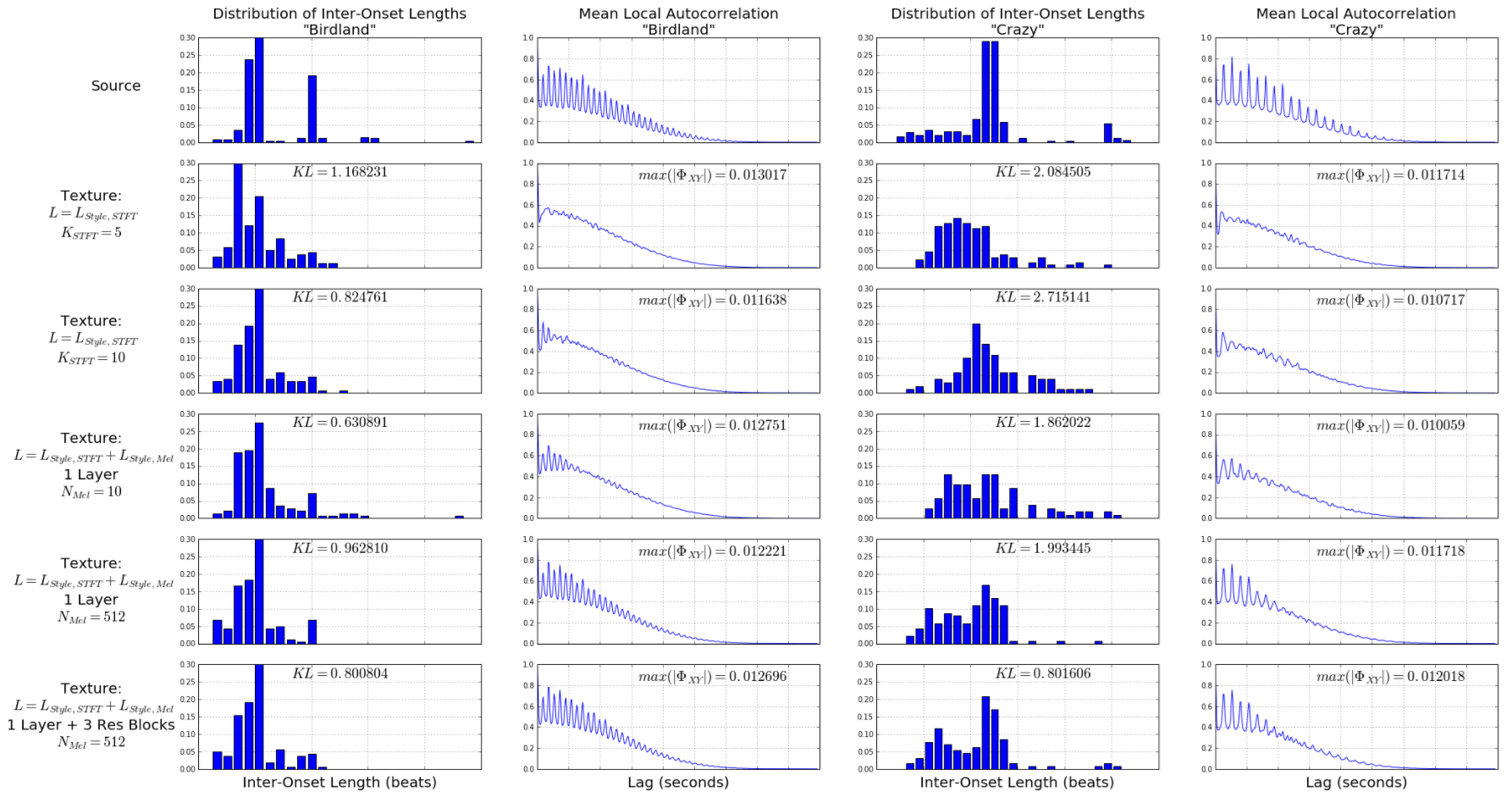
Figure 4: Columns 1 and 3: comparison of inter-onset lengths distribution and KL divergence from the source distribution for a texture generation example as the effective receptive field increases in time. Columns 2 and 4: mean local autocorrelation plots showing the increase in hierarchical rhythmic structure of the audio without any significant increase in the maximum cross-correlation value.
| Example 1 | |
|---|---|
| Source | |
| Textures | |
| Example 2 | |
| Source | |
| Textures |
Experiment 4.2: Testing Key Invariance
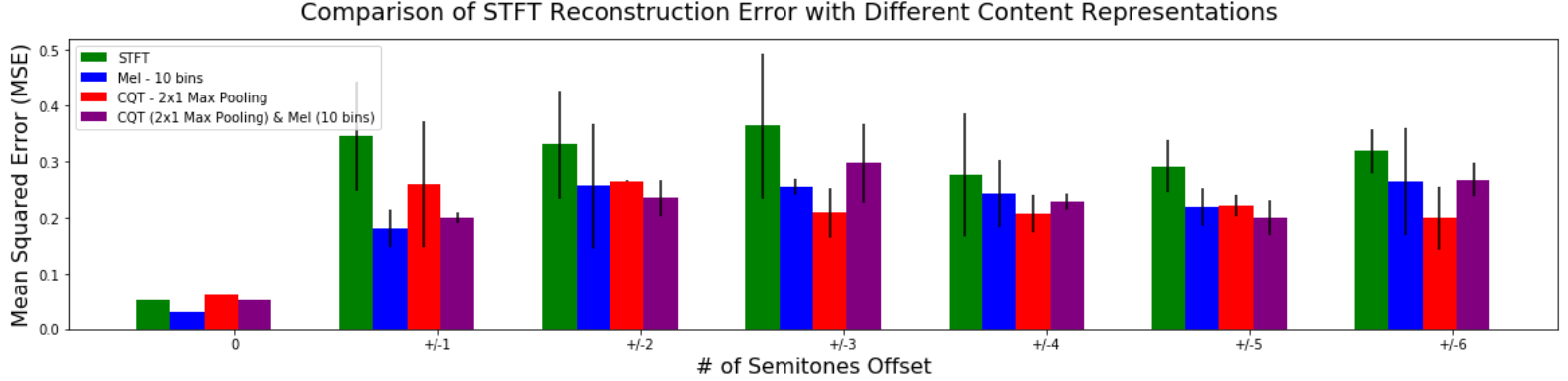
Figure 5: Comparison of the error with different content-based representations for a task where the content and style audio is exactly the same except for key. The x-axis represents varying semi-tone offsets in musical representation. The first point on the left of 0 semi-tone offset represents a trivial problem where both content and style are exactly the same signals. We plot the error in the log-magnitude STFT representations to show the overall signal error.
| Source | |
|---|---|
| STFT Reconstructions | |
| Mel Reconstructions | |
| CQT Reconstructions | |
| Mel + CQT Reconstructions |
Experiment 4.3: Comparison of examples with best implementation.
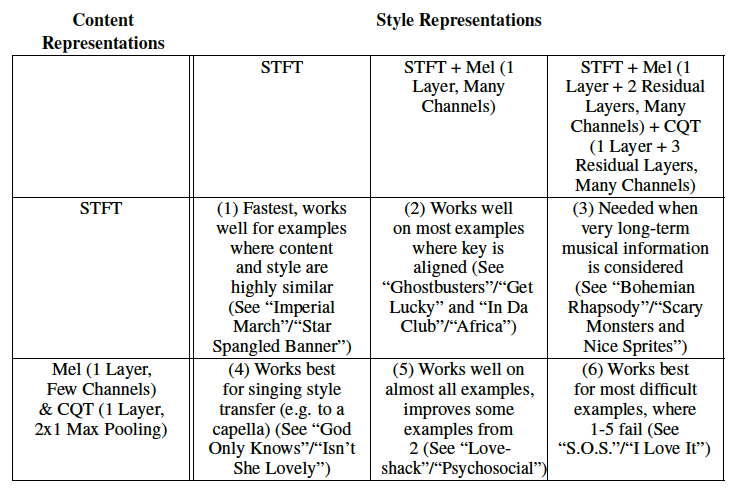
The table below gives which content and style representation combinations work best for different types of examples, with a corresponding style transfer pair in the below examples that works best with that combination of loss terms
| Example 1 | |
|---|---|
| Content | |
| Style | |
| Results | |
| Example 2 | |
| Content | |
| Style | |
| Results | |
| Example 3 | |
| Content | |
| Style | |
| Result | |
| Example 4 | |
| Content | |
| Style | |
| Result | |
| Example 5 | |
| Content | |
| Style | |
| Result | |
| Example 6 | |
| Content | |
| Style | |
| Result (Content - Mel+CQT, Style - Mel (2 Resid) + CQT (3 resid) | |
| Result (Content - STFT, Style - Mel (2 Resid) + CQT (3 resid) | |
| Example 7 | |
| Content | |
| Style | |
| Result |